Një pjesë e konsiderueshme e infrastrukturës që e ka Gjirafa, ka të bëjë me procesimin e shumë të dhënave në prapavijë të cilat nuk shihen drejtëpërdrejtë nga përdoruesi. Kjo përfshin procesimin e aktiviteteve të shumta siq janë vizitat e produkteve, shikimet e videove, shfletimi i shpalljeve, kërkimet e autobusave e shumë të tjera.
Këto procesime bëhen përmes aplikacioneve që punojnë 24/7 pa ndërprerë, në prapavijë, në një nga serverët e shumtë që i ka Gjirafa. Duke u shtuar numri i produkteve dhe i të dhënave gjatë viteve, është shtuar drastikisht edhe numri i këtyre aplikacioneve që bëjnë procesime të tilla. Përveq sfidave të zhvillimit të këtyre aplikacioneve, një sfidë e madhe është edhe monitorimi i tyre. Për shkak që ata punojnë në prapavijë, është më e vështirë të vërehet nëse ndonjëri prej tyre ka ndonjë problem. Normal, varësisht prej aplikacionit, zhvilluesit përgjegjës kanë bërë zgjidhje për monitorim të atij aplikacioni speficik. Por, kjo ka ndikuar në shumë zgjidhje të ndryshme për një problem të njejtë.
Ky problem është theksuar më shume kur e kemi zhvilluar sistemin tonë të brendshëm për procesimin e të dhënave në kohë reale (se si punon ky sistem nevojitet një artikull ne vete, por një përshkrim të shkurtër mund ta gjeni tek prezentimi që e kam bërë në debugCon: https://youtu.be/cRDQMgxK_V4). Procesimi i të dhënave bëhet duke përdorur arkitekturën publish-subscribe, që do të thotë se ekzistojnë shumë konsumues (“consumers”) në prapavijë që i procesojnë këto të dhëna që vijnë vazhdimisht. Këta konsumues janë një prej shume atyre aplikacioneve që i përmendëm në fillim të këtij posti dhe janë të shpërndarë në shumë datacenters të ndryshëm nëpër botë.
Duke pasur aq shumë consumers të shpërndarë, lind problemi i monitorimit. Si mund ta dijmë se të gjithë konsumuesit janë duke punuar, sa resurse përdorin, apo mos është ndalur ndonjëri prej këtyre aplikacioneve. Problemi më i madh është kur aplikacioni ndalet nga ndonjë shkaktar i jashtëm: ndalja e rrjetit, probleme me memorie apo ndalje totale e serverit. Në këto raste aplikacioni nuk ka se si të lajmërojë se është ndalur. Për këtë nevojitet një sistem i jashtëm që i monitoron të gjithë këto aplikacione.
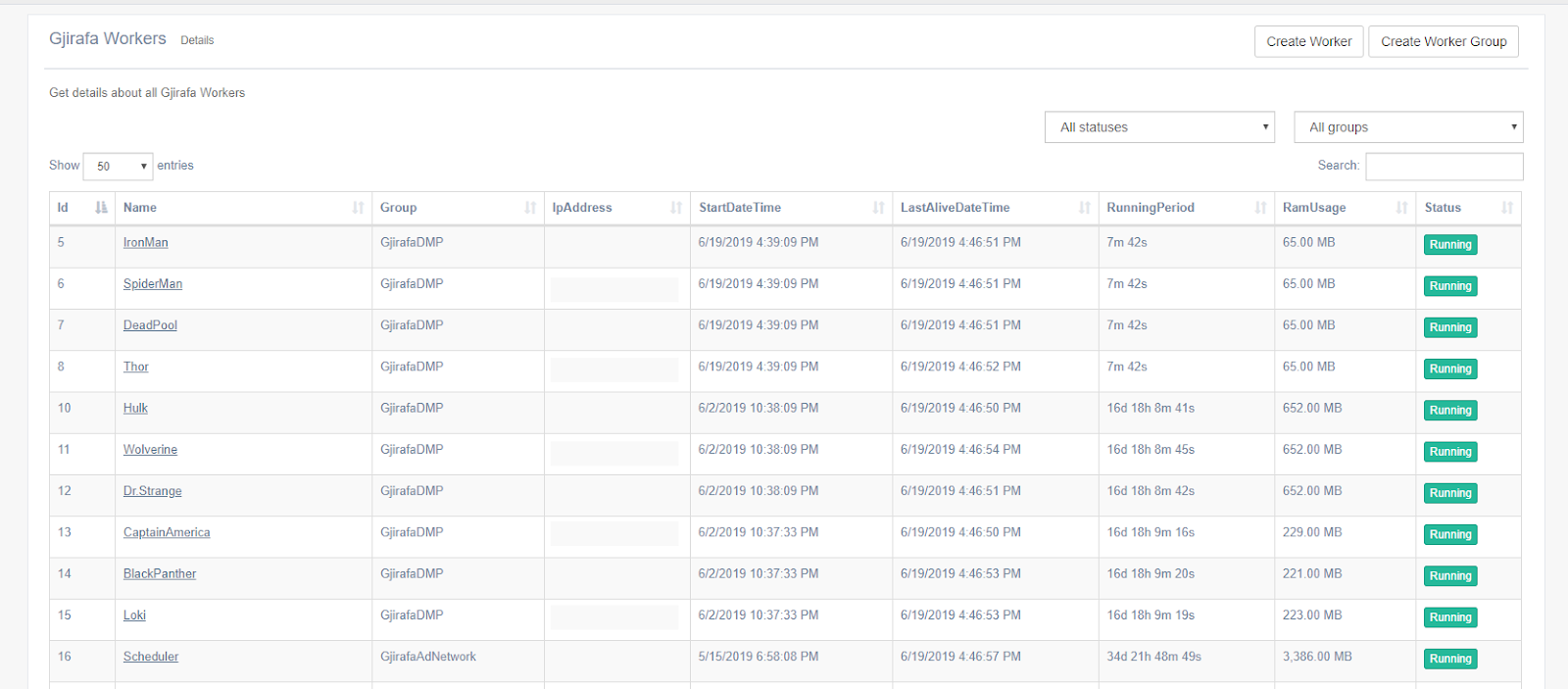
Njihuni me GjirafaCaptain. GjirafaCaptain (nga këtu i referohemi shkurtimisht me “kapiteni”), është sistemi që ne e kemi zhvilluar për të bërë monitorimin e gjithë ketyrë aplikacioneve. Ky sistem ndihmon në monitorimin e të gjithë aplikacioneve që punojnë në parapvijë, tregon se a është duke punuar apo është ndalur një aplikacion, njofton nëse ndonjëri nga aplikacionet ka ndonjë problem dhe poashtu ofron një zgjidhje të centralizuar për ruajtjen e logs-ave për të gjithë aplikacionet.
Gjatë zhvillimit të kapitenit, jemi munduar të implementojmë një zgjidhje që do të kërkonte sa më pak punë që të implementohet nëpër të gjitha aplikacionet ekzistuese si dhe të jetë i pavarur nga ato.
Për këtë aryse e kemi krijuar një librari të brendshme të quajtur GjWorker. Arsyeja pse e kemi quajtur GjWorker është për shkak se këto aplikacione që punojnë në prapavijë ne i quajmë “workers”. Pasi që ne përdorim teknologjinë e C#, kjo librari është zhvilluar në formë të një Nuget-i të brendshëm, që instalohet shumë lehtë. E tëra çka duhet të bëj një nga zhvilluesit tanë (për të monitoruar një aplikacion të tij) është të inicializojë këtë librari në startim të aplikacionit duke i japur numrin identifikues (ID) të atij aplikacioni. Për të pasur ID-në e një aplikacioni specifik, zhvilluesi duhet të krijojë një aplikacion brenda kapitenit, duke i japur informatat e nevojitura rreth aplikacionit, që përfshijnë një emër unik si dhe përshkrimin se çfarë pune kryen një aplikacion. Aplikacionet i takojnë grupeve të caktuara. Pas inicializimit, kjo librari e krijon një “Timer” në background që çdo 3 sekonda i dërgon informatat rreth gjendjes së aplikacionit (RAM, uptime etj.).
Një pjesë e kodit është e paraqitur më poshtë.
public static void InitializeWorker(
int workerId,
bool runInDebug = true,
bool logInConsole = true)
{
var processName = Process.GetCurrentProcess().ProcessName;
var ramCounter = new PerformanceCounter("Process", "Working Set", processName);
_worker = new GjirafaWorker
{
Id = workerId,
RamCounter = ramCounter,
StartDateTime = DateTime.Now,
Guid = Guid.NewGuid().ToString().Replace("-", ""),
RunInDebug = runInDebug,
LogInConsole = logInConsole,
MachineName = Environment.MachineName,
IpAddress = GetIpAddress()
};
var timer = new Timer(SendState, null, TimeSpan.FromSeconds(0), TimeSpan.FromSeconds(3));
}
private static void SendState()
{
if (IsInDebug() && !_worker.RunInDebug)
return;
var ramUsage = (decimal)_worker.RamCounter.NextValue() / 1024 / 1024;
var gjWorkerState = new GjirafaWorkerState
{
Id = _worker.Id,
RamUsage = _worker.RamUsage,
StartDateTime = _worker.StartDateTime,
StateDateTime = DateTime.Now,
Guid = _worker.Guid,
IpAddress = _worker.IpAddress
};
_publisher.Publish(StateQueuename, gjWorkerState));
}
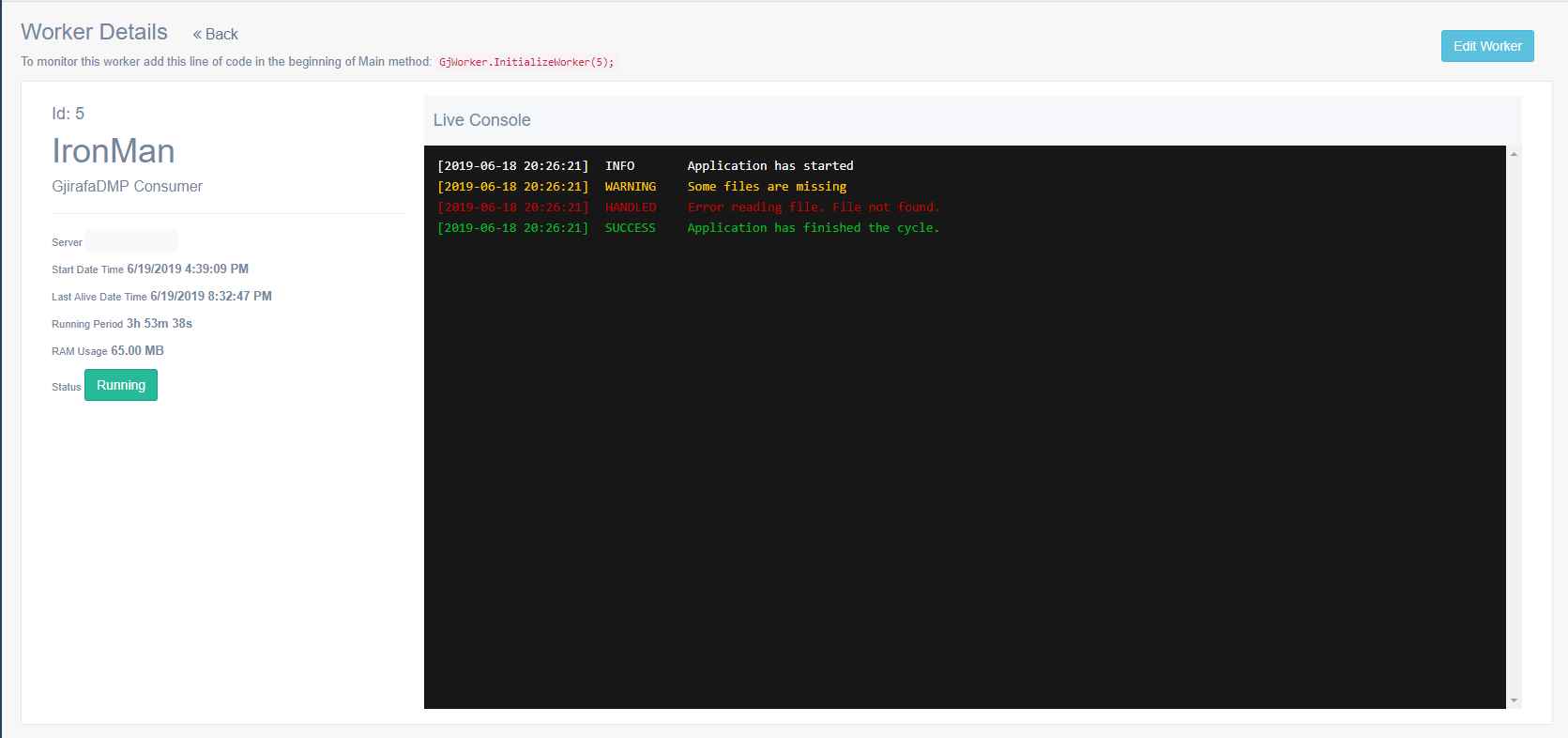
GjWorker ofron edhe mundësine për ruajtjen e logs-ave të ndryshëm brenda aplikacionet. Llojet e logs-ave që i ruan libraria përfshijnë: Info, Warning, Success dhe Error. Në secilin prej këtyre logs zhvilluesi mund të ruajë çfarëdo informate shtesë që do t’i ndihmojë në monitorim sa më të mirë të punës së aplikacionit. Të gjithë këto logs ruhen përgjithmonë në kapiten. Përveq këtyre logs, GjWorker poashtu monitoron nëse ndodh ndonjë error që nuk është trajtuar nga zhvilluesi dhe ndikon në ndaljen e punës së aplikacionit. Këto errore GjWorker i trajton si Unhandled dhe dërgon një njoftim të menjëhershëm.
void Info(string message, Dictionary<string, object> data = null); void Success(string message, Dictionary<string, object> data = null); void Warning(string message, Dictionary<string, object> data = null); void Exception(string message, Exception exception, Dictionary<string, object> data = null);
Shembuj të përdorimit:
GjWorker.Success("Cycle finished",
new Dictionary<string, object>
{
{ "elapsed", stopWatch.Elapsed },
{ "cycleNr", cycleCount }
});
//dictionary eshte optional, mundet edhe
GjWorker.Success("Cycle finished");
//metoda tjera
GjWorker.Info("Data read from database...");
GjWorker.Warning("Object is null",
new Dictionary<string, object>
{
{ "id", id }
});
Duke marrë parasysh qe secili aplikacion do të dërgojë gjendjen e tij çdo 3 sekonda tek kapiteni, atëherë kemi të bëjmë më 28,800 mesazhe në ditë për një aplikacion. Nëse e marrim edhe një mesatare prej 10 logs-ave shtesë për minutë, për një aplikacion, atëherë kemi edhe rreth 14.400 mesazhe tjera në ditë. Kjo na jep përafërsisht rreth 43,200 mesazhe nga një aplikacion i vetëm në ditë (Pjesa e dytë e logs-ave është vetëm një mesatare e parashikuar dhe nuk do të thotë që është numër i saktë. Ka aplikacione që kanë shumë më shumë logs, e ka disa tjerë që kane fare pak brenda një ditë). Kur e llogarisim që i kemi mbi 50 aplikacionë të ndryshme, atëherë kemi të bëjmë me mbi 2,000,000 mesazhe në ditë nga aplikacione të ndryshme.
Kjo na sjell tek problemi tjetër. Ruajta dhe procesimi i këtyrë të dhënave. Si ta dizajnojmë një infrastrukturë që mund t’i përballojë gjithë këto mesazhe, të jetë e besueshme dhe e sigurt që nuk do të humb asnjë mesazh i dërguar, si dhe ta bëjë të lehtë dhe të shpejt qasjen në këto të dhëna në çfarëdo kohe.
Zgjidhja e parë që e kemi bërë ka qëne krijimi i një API të shpërndarë në shumë hoste me një load-balancer përpara, që përdorej për shpërndarjen e kërkesave. Çdo mesazh për gjendjen e aplikacionit apo log i aplikacionit është ruajtur përmes këtij API, duke bërë HTTP request me informatat e duhura. Kjo zgjidhje, edhe pse ka funksionuar mjaft mirë, ka pasur problemet e veta. Si problem parësor, mund ta konsiderojmë load-balancerin, që bën balancimin e kërkesave në mes API-ve të ndryshëm. Nëse ky load-balancer do të kishte ndonjë problem të çfarëdoshëm, qoftë me rrjet, qoftë më memorie apo ndalim të ndonjë shërbimi specifik, atëherë kjo do të ndikonte në ndalimin apo vonimin e kërkesve tek API i kapitenit, duke shfaqur probleme serioze. Çdo vonim i një kërkese për tek API, do të thotë se do të vonohej edhe puna e aplikacioneve që e përdorin GjWorker. Vonesa të zgjatura mund të ndikojnë edhe në ndaljen e punës së aplikacionit për shkaqe të shumta. Kjo ka krijuar një lloj varësie në mes të aplikacionit që po ekzekutohet dhe kapitenit, më konkretisht GjWorker-it që përdoret për monitorim. Edhe pse këto thirrje në API bëhenin duke përdorur metodat async, përsëri ekzistonin hapësira për probleme të theksuara.

Zgjidhja e dytë dhe aktuale të cilën e kemi implementuar, përdor modelin publish-subscribe në dy nivele të ndryshme.
Niveli i parë është brenda vetë aplikacionit, ku krijohet një ConcurrentQueue në të cilën ruhen të gjitha logs-at që duhet të dërgohen tek kapiteni. Gjatë inizializimit të GjWorker, krijohet një Thread në prapavijë, i cili vazhdimisht e shikon se mos ka ndonjë log në Queue që duhet të dërgohet tek kapiteni. Me këtë model, ne e kemi pavarësuar ekzekutimin e aplikacionit nga monitoruesi (GjWorker), që do të thotë se këto logs do të trajtohen në mënyrë të pavarur dhe nuk do të ndikojnë në ndaljen apo ngadalësimin e punës së aplikacionit.
private static readonly Thread ConsumerThread = new Thread(ConsumeLogs);
public static void Info(
string message,
Dictionary<string, object> data = null)
{
var dateTime = GjDateTime.Now;
if (_worker.LogInConsole)
WriteInConsole(GjirafaWorkerLogTypes.INFO, dateTime, message, ConsoleColor.White);
if (IsInDebug() && !_worker.RunInDebug)
return;
var log = new GjirafaWorkerLog
{
Id = Worker.Id,
DateTime = dateTime,
Message = message,
Type = GjirafaWorkerLogTypes.INFO,
Guid = Worker.Guid,
Data = data,
MachineName = Worker.MachineName,
IpAddress = Worker.IpAddress
};
Logs.Add(new Tuple<string, object>(LogsQueueName, log));
}
private static void ConsumeLogs()
{
while (true)
{
Tuple<string, object> log = null;
try
{
log = Logs.Take();
}
catch { }
if (log != null)
{
_publisher.Publish(log.Item1, log.Item2);
}
}
}
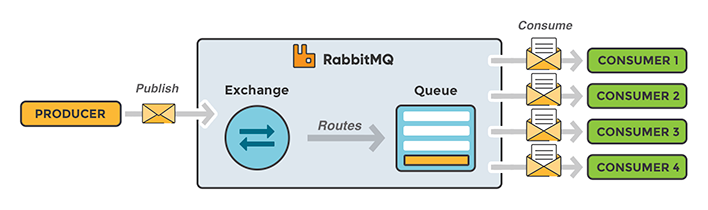
Niveli i dytë është një Queue global që përdoret nga të gjithë aplikacionet për të dërguar të dhënat e tyre. Për këtë kemi përdorur RabbitMQ. RabbitMQ është një open-source message broker, që shërben si urë komunikuese ndërmjet aplikacioneve të ndryshme që nuk komunikojnë derjtëpërdrejtë me njëra tjetrën. Se si funksionon më detajisht RabbitMQ mund t’i gjeni informatat e nevojshme në faqen zyrtare apo në dokumentimet e ndryshme. Por, për rastin tonë na duhet t’i dijmë dy koncepte kryesore rreth kësaj librarie.
Janë dy modele kryesore të publish-subscribe që mund t’i përdorim përmes RabbitMQ (në realitet janë më shumë, por ne do t’i përdorim këta dy):
- Queue
- Exchange (fan-out)
Modeli i Queue garanton që një mesazh i publikuar do të pranohet dhe procesohet vetëm një herë nga vetëm një konsumues i caktuar. Kjo do të thotë se kur e publikoni një mesazh në një Queue, RabbitMQ do ta dërgojë këtë mesazh në një nga konsumuesit që jane duke pritur në këtë queue dhe do të pres për konfirmimin e procesimit të mesazhit. Në rast të ndonjë dështimi, RabbitMQ e dërgon këtë mesazh tek konsumuesi i rradhës.
Modeli i Exchange, mundëson dërgimin e një mesazhi tek shume konsumues në të njëjtën kohë pa u brengosur se a e kanë pranuar apo jo mesazhin. Kjo do të thotë se në të njejtën kohë një exchange mund të ketë shume konsumues duke pritur për mesazhe apo edhe asnjë. RabbitMQ i dërgon mesazhin vetëm atyre konsumuesve që janë aktiv në atë moment në atë Exchange të caktuar.
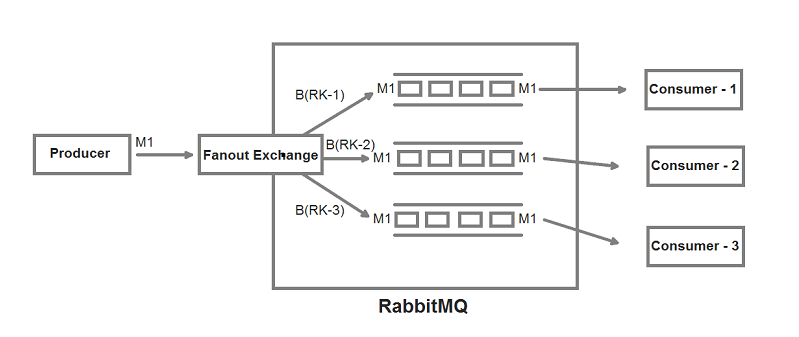
Si sigurohemi që RabbitMQ do ti dërgojë të gjitha mesazhet pa humbur ndonjë? Zgjidhja është duke krijuar një Cluster të RabbitMQ. Ne i kemi tre hoste të ndryshme të RabbitMQ që komunikojnë vazhdimisht me njëri tjetrin. Poashtu edhe libraria jonë e brendshme që komunikon me cluster-in tonë të RabbitMQ, është e implementuar në atë mënyrë që në rast se humbet komunikimi me ndonjërin nga hostet e RabbitMQ, aplikacioni automatikisht tenton të lidhet me hostin tjetër. Kjo nuk e ndalon problemin që mund të shfaqet nësë të tre hostet kanë probleme apo edhe ndalen, por probabiliteti i një rasti të këtillë është aq i vogël sa që nuk ja vlen të bëhet ekstra punë që të parandalohet. Prej krijimit të këtij cluster-i e gjer tek ky moment që jam duke e shkruar këtë artikull kanë kaluar më shume se 300 ditë pa asnjë problem të vetëm me RabbitMQ, përkundër faktit që kemi pasur dhjetëra miliona mesazhe të publikuara në ditë.
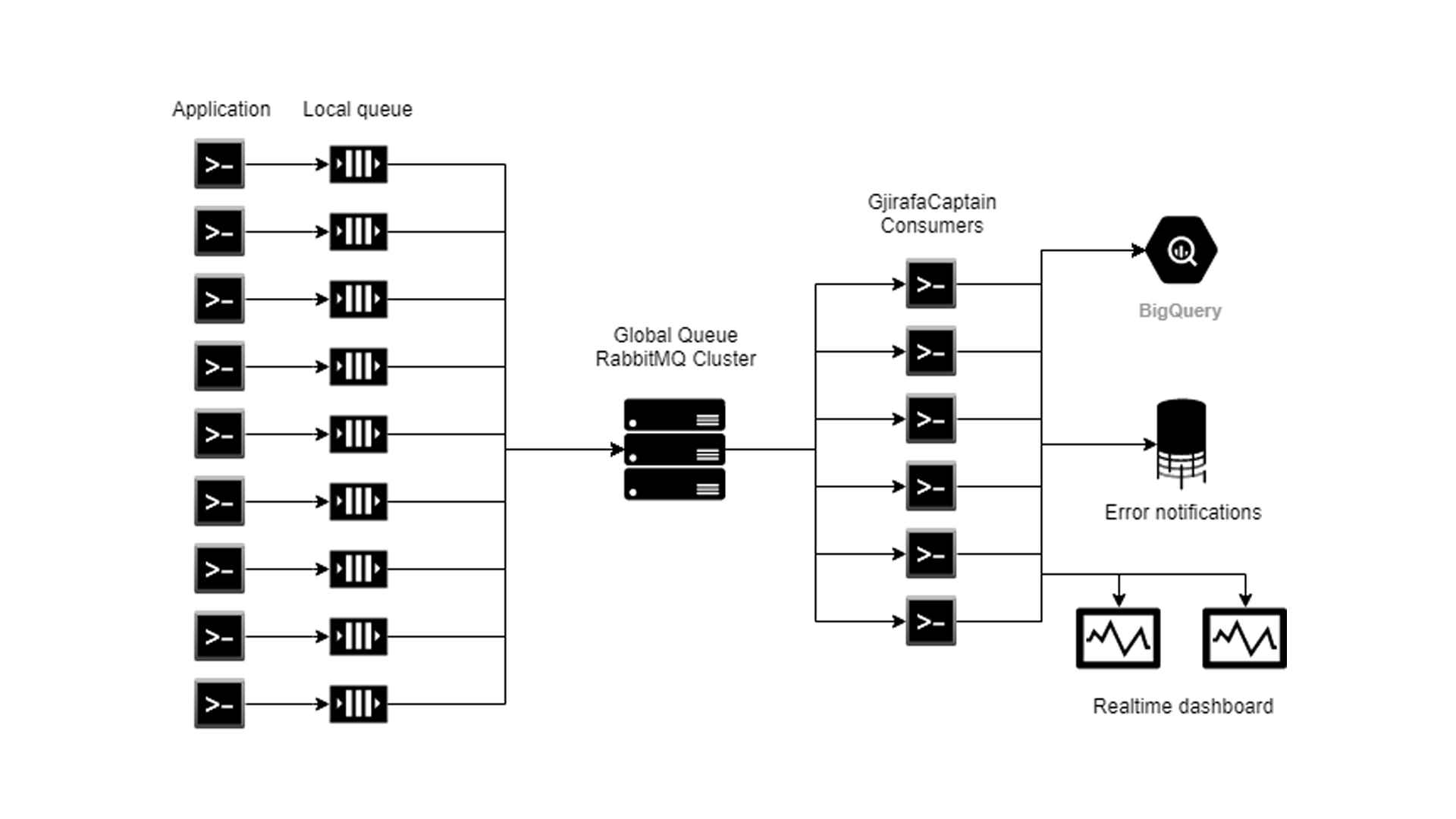
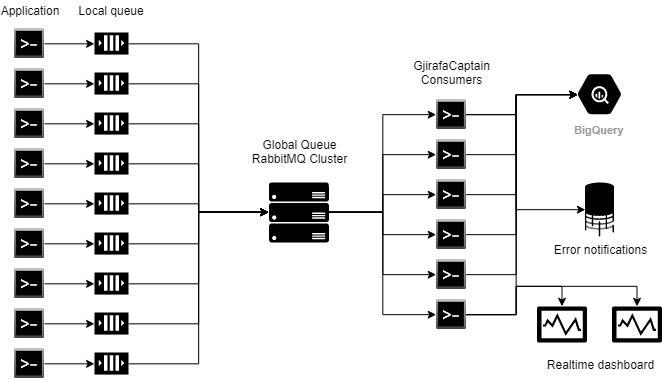
Libraria GjWorker e dërgon çdo mesazh (që mund të përmbajë informatat rreth gjendjes së aplikacionit përkatës, apo informatat rreth një log-u të caktuar) në një Queue globale të centralizuar. Më pas në prapavijë janë shume konsumues të ndryshëm që vazhdimisht i presin këto mesazhe dhe i përpunojnë ato për qëllime të monitorimit të infrastrukturës në përgjithësi.
Kapiteni përdorë disa shërbime për të procesuar të dhënat. Pas çdo lajmërimi për gjendjen e aplikacioneve kapiteni i përditëson të dhënat e atij aplikacioni ne databazë, qe është një SQL Server Cluster, duke i përditësuar kohën e fundit aktive të aplikacionit, uptime si dhe memorien që e përdorë. Poashtu, logs-at që vijnë të gjitha ruhen ne Google BigQuery që të na lejojë qasjë të mëvonshme nëse dëshirojmë t’i shikojmë disa logs-a specifik.
Përveq në BigQuery, kapiteni poashtu i dërgon këto logs në një web-console, duke i mundësuar zhvilluesve në kohë reale të monitorojnë çfarëdo që po ndodh me një aplikacion përkatës. Për një funksionalitet më të mirë dhe më të sigurt GjirafaCaptain është i hostuar nëpër disa datacenters të ndryshëm nëpër botë. Kjo do të thotë se në një kohë të caktuar një përdorues (në këtë rast një nga zhvilluesit e Gjirafës) mund të jetë i lidhur në hostin nr.1 ndërsa përdoruesi tjetër në hostin nr2. Konsumuesit që i procesojnë të mesazhet që vijnë nga aplikacionet e ndryshme duhet të sigurohen që këto mesazhe të shkojnë tek të dy përdoruesit e kapitenit. Kjo arrihet përmes Exchange. Ne startim të web aplikacionit të GjirafaCaptain, secili host abonohet në një Exchange specifik dhe pret për ndonjë mesazh të ri. Në rastin që vjen një mesazh i ri nga ndonjë prej procesuesve, kapiteni e dërgon këtë mesazh tek të gjithë përdoruesit aktiv në web-console. Këtu kemi të bëjmë me komunikimin server - klientë. Kjo arrihet përmes librarisë SignalR, që mundëson komunikimin në kohë reale në mes klientëve dhe serverëve në projektet e ASP.NET. Në momentin që një përdorues e hap një dashboard të një aplikacioni të caktuar në kapiten, atëhere ai atuomatikisht i bashkohet grupit të të gjithë përdoruesve që janë për momentin në atë faqe. Kur pranohet një mesazh të ri nga aplikacioni përkatës, kapiteni i dërgon të gjithë përdoruesve që i takojnë këtij grupi, mesazhin, i cili më pas shfaqet në console tek përdoruesi.
Pasi që të gjithë këto mesazhe ruhen në mënyrë permanente në BigQuery, kjo i mundëson zhvilluesve të shikojnë logs-at nga e kaluara pa ndonjë limit kohor. Ata poashtu e kanë mundësinë të zgjedhin logs-at për një periudhë të caktuar, prej disa orë e deri tek disa ditë, si dhe të filtrojnë logs-at në bazë të llojit (success, warning, error etj.)
Gjer më sot, janë bërë disa muaj prej që e kemi implementuar këtë sistem dhe jemi duke e përdorur në shumicën prej aplikacioneve tona. Mund të themi se na ka lehtësuar shumë punën rreth menaxhimit dhe monitorimit të aplikacioneve dhe me raste edhe në gjetjen e disa problemve të cilat më herët nuk e kemi ditur se ekzistonin.
Në planet e së ardhmes është edhe startimi dhe ndalja e këtyrë aplikacioneve në mënyrë atuomatike nga kapiteni. Për momentin këto aplikacioni startohet apo ndalen manualisht nga vetë zhvilluesit apo edhe nga Task Manager-ët e hosteve të ndryshme të cilat janë të konfiguruara manualisht nga zhvilluesit. Për momentin jemi duke bërë disa testime se di mund të arrijmë ta automatizojmë këtë proces. Ideja është që aplikacionet të ngarkohen si binary-executable files në web në kapiten dhe më pas kapiteni të kujdeset se ku do të ekzekutohet ai aplikacion. Kjo do të lehtësontë shumë një pjesë të madhë të punës së ekipit tonë të zhvilluesve, por për momentin nuk kemi ende ndonjë implementim konkret. Me gjasë kjo do të jetë tema për ndonjë artikull të ardhshëm.

