Shumë nga produktet e Gjirafës, kanë nevojë të dijnë lokacionin momental të përdoruesve të tyre. Përveq që ndihmon në analizë të të dhënave për të ditur se në cilat vende kanë më së shumti përdorues, kjo ndihmon edhe në funksionimin më të mirë të disa produkteve: përmbajtjes në gjirafaVideo, shitja e produkteve në gjirafa50 dhe gjirafaMall apo edhe shfaqja e reklamave të targetuara me anë të gjirafaAdNetwork. Në këtë artikull do të shpjegojmë si e kemi dizajnuar dhe implementuar një shërbim të brendshëm (API) në Gjirafa, i cili ofron informatat mbi gjeo-lokacionin e një IP adrese dhe të cilin e përdorim intensivisht në të gjitha produktet tona.
Një nga mënyrat më të shpeshta për të përcaktuar lokacionin e përdoruesit që viziton një faqe në internet është përmes IP adresës së tyre. Edhe pse IP adresa nuk e tregon në mënyrë të përpiktë lokacionin e përdoruesit, ajo në shumicën e rasteve e tregon të paktën shtetin në të cilin ndodhet përdoruesi. Por, si mund ta dijmë shtetin nga një IP adresë?
Zakonisht IP adresat blihen nga një furnizues i internetit në rangje të caktuara. P.sh. kompania X bën kërkesën për të blerë IP adresat në rangun 10.11.12.13 deri tek 10.11.12.30. Kur të pranohet kërkesa dhe jepet rangu i IP adresave, IANA e bën regjistrimin se kush e posedon këtë rang. Këto informata janë të hapura. Me këto të dhëna e dijmë se përdoruesit që kanë cfarëdo IP adrese që ndodhet brenda këtij rangu, janë përdorues të Kompanisë X dhe duke e ditur që Kompania X është e regjistruar në Kosovë mund të konkludojmë se këta përdorues janë nga Kosova. Në bazë të kësaj, duke i pasur të gjitha rangjet e adresave ne mund të dijmë për shumicën e përdoruesve prej cilit shtet janë. Saktësia e këtyre informata nuk mund të dihet, por shumë nga kompanitë që ofrojnë databaza të informacioneve mbi gjeo-lokacionet e IP adresave pretendojnë për një saktësi deri në 95%.
Ekzistojnë API të shumtë të cilët japin informacione mbi gjeo-lokacionin e një IP adrese specifike. Këta API zakonisht janë web shërbime, ku me një kërkesë të thjeshtë mund t’i merrni të gjitha informatat e duhura në cfarëdo formati. Disa nga këto shërbime janë edhe falas, por me limite. Për t’u përdorur intensivisht, duhet të përdoren pakot premium, pra me pagesë. Duke marrë parasysh që ky shërbim do të përdorej intensivisht, kostoja e përdorimit të një API të tillë do të ishte shume e madhe dhe jo shumë efikase.
Kjo ka lindur nevojën për të zhvilluar një API të brendshëm që do të ofronte informata mbi gjeo-lokacionin e një IP adrese. Ky API duhej të ishtë i gatshëm të kthente rezultatet shpejt (nën 20 milisekonda) dhe të përballonte shumë kërkesa brenda një dite (deri 10 milion).
Kompanitë sikurse Ip2location, MaxMind, Tamo Soft, DB-IP, Ipinfo and IPligence ofrojnë versione falas të databazës me të gjitha rangjet e IP adresave të blera nga furnizuesit e internetit në gjithë botën. Ju mund të shkarkoni këtë databazë ku do të ketë afër 4 milion rangje të ndryshme të IP-ve dhe informatat mbi lokacionin e furnizuesve të internetit që i kanë këto adresa. Një shembull se si duken informatat e shkarkuara:

Tani që i kemi siguruar të dhënat e nevojshme vazhdojmë me implementimin e API që do të na jap shtetin e një IP adrese të caktuar.
Pasi që të dhënat i kemi në rangje të ndryshme, për cdo IP adresë që vjen në API, ne duhet ta krahasojmë atë me të gjitha rangjet deri sa të gjejmë rangun në të cilin takon kjo IP e caktuar dhe të marrim shtetin e këtij rangu. Kjo çasje e ka kompleksitetin kohor O(N), që do të thotë në rastin më të keq një IP duhet të krahasohet më të gjitha rangjet ekzistuese, edhe pse në praktikë mesatarja është më e vogël. Pra, për një IP, API mund të bëjë deri në 4 milionë krahasime deri sa të gjej rangun e duhur. Edhe pse për një kompjuter modern një procesim i tillë nuk zgjat shumë, duhet të kemi parasysh që kjo do të bëhet miliona herë brenda ditës. Kjo e rrit procesimin shumë dhe me këtë rast mund të ndikojë në ngadalësim të punës së API. Për këtë arsye na duhet një strukturë më e mirë e të dhënave.
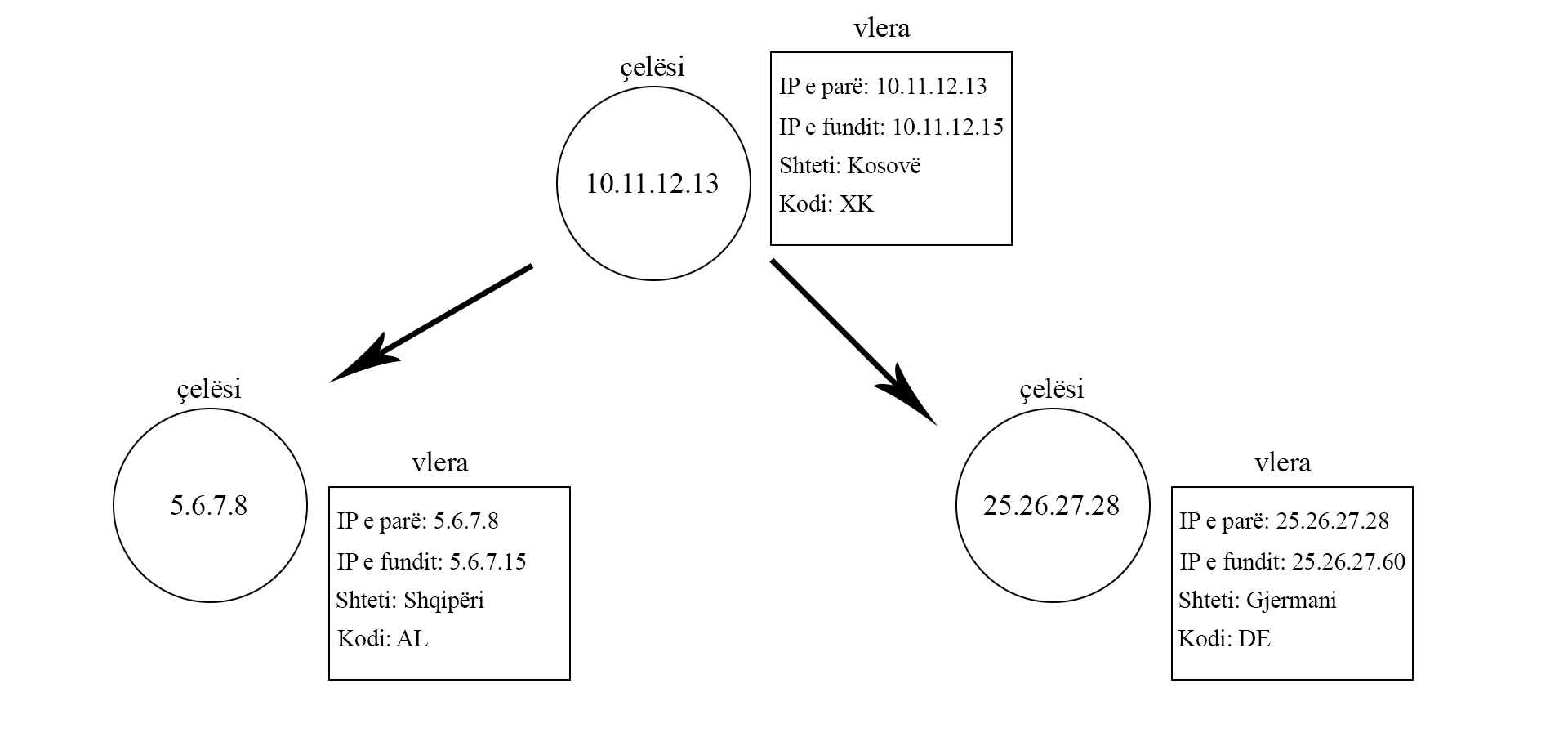
Le të analizojmë së pari të dhënat që i kemi. Nga fotoja mund të shohim se çdo rang i IP adresave e ka një IP adresë fillestare dhe një IP mbaruese të rangut që janë të kthyera në reprezentimin e tyre decimal. Duke i kthyer këto adresa në numrat përkatës ne mund t’i rendisim këto numra nga më i vogël tek më i madh dhe më pas të përdorim këtë për kërkim më efiqient.
Një strukturë e përshtatshme për këtë lloj të të dhënave është pema (tree). Një pemë përmban një nyje kryesore që permban një celës më të cilën identifikohet dhe ka dy femijë, një në të majtë që ka vlerë më të vogël se çelësi i nyjes dhe një në të djathtë që ka vlerë të madhe se çelësi i nyjes. Çdo nyje brenda pemës paraqet një nën-pemë. Me anë të kësaj kur bëjmë ndonjë kërkim fillojmë prej nyjes kryesore dhe bëjmë krahasimet. Nëse vlera është e njejtë me çelësin e nyjes e kthejme vlerën e asaj nyje. Nëse është me e vogël vazhdojmë në nyjen e majtë dhe anasjelltas në nyjen e djathtë. Me këtë e zvogëlojmë drastikisht numrin e krahasimeve.
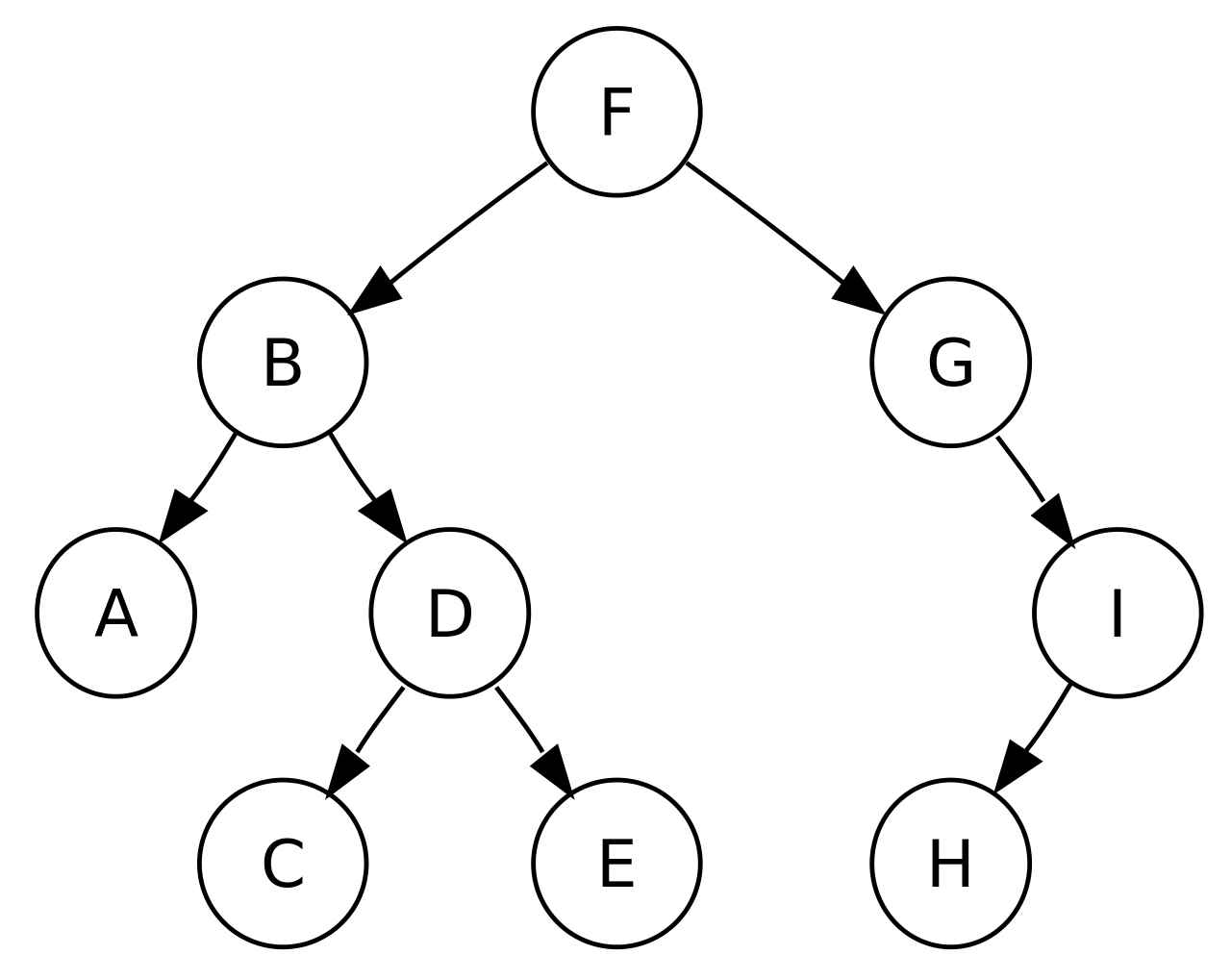
Edhe pse në këtë rast kompleksiteti kohor zbret drastikisht, ende në rastin më të keq kompleksiteti kohor është O(N), sepse kjo varet në bazë të renditjes së insertimit të të dhënave. Për të përmirësuar performancën mund të përdorim një pemë e cila garanton balancimin e çelësave (Self-balancing binary search tree). Pemët e balancuara e kanë kompleksitetin kohor të garantuar O(logN). Ekzistojnë implementime të ndryshme të pemëve të balancuara, por ne do të përdorim Red&Black Tree.
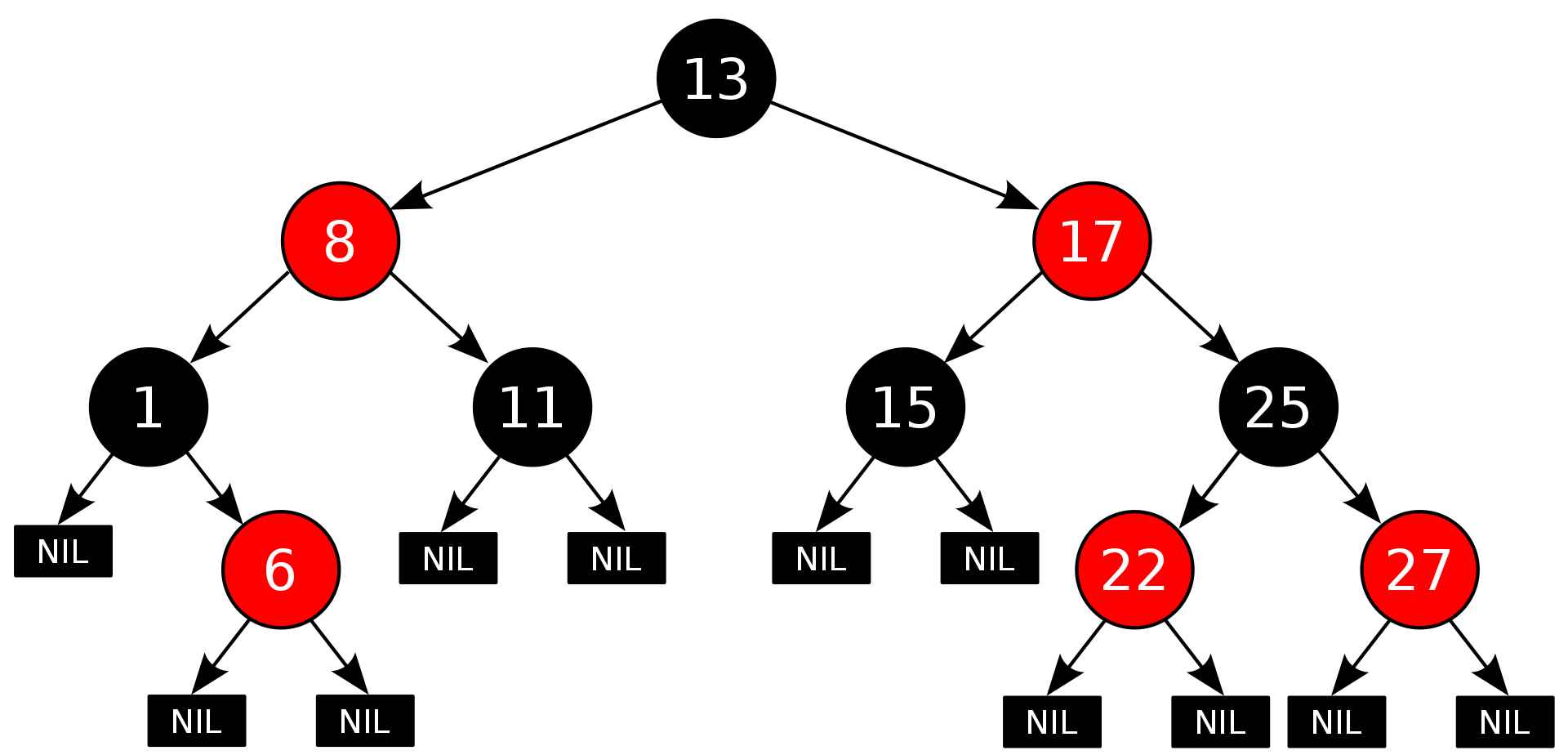
Kjo do të thotë se në rastin tonë ku kemi afër 4 milionë rangje (çelësa të ndryshëm) do të kemi maksimalisht 22 krahasime, për dallim nga 4 milionë krahasime qe i kemi pasur në rastin e parë.
Kur të bëjmë një kërkim në një pemë, ne i japim çelësin që dëshirojmë dhe me pas pema na kthen vlerën e atij çelësi (nëse ekziston). Por, në rastin tonë ne i kemi rangjet e IP adresave (IP-në e parë dhe të fundit të rangut), që do të thotë në shumicën e rasteve IP adresën që do të kërkojmë nuk gjendet si numër i saktë, por është diku në mes të këtyre rangjeve. Një zgjidhje mund të jetë të insertojmë të gjitha IP adresat e mundshme brenda këtyre rangjeve që i kemi. Por, siq e dimë ekzistojnë 2^32 kombinime të mundshme, që do të thotë se kemi mbi 4 miliardë IP të ndryshme, që do të zinte shumë hapësirë në memorie.
Për fat të mirë nuk kemi nevojë t'i ruajmë të gjitha IP adresat në memorie. Ekziston një qasje tjetër. Pemët përveq kërkimeve eksplicite, kanë edhe dy metoda ndihmëse që jane floor() dhe ceil(). Në rastin tonë do të përdorim metodën floor. Kjo metodë kthen çelësin më të madh në pemë që është më i vogël ose i barabartë me çelësin që i japim ne.
P.sh nëse në pemë i kemi çelësat [ 1, 5, 7, 13] dhe ne kërkojmë floor për numrin 10 atëherë do të na kthehet çelësi 7.
Në rastin me rangjet e IP adresave, ne kemi IP-në e parë dhë të fundit të rangut. Ajo çfarë mund të bëjmë është që ta përdorim IP e parë të rangut si çelës në pemë. Në këtë rast kur kërkohet një IP adresë, ne e konvertojmë atë në formatin decimal, dhe e kërkojmë floor të këtij numri në pemën e të gjitha rangjeve. Më pas e shikojme se a ekziston kjo IP adresë brenda rangut të vlerës së kthyer nga floor, dhe nëse po e kthejmë shtetin e rangut.
Pjesa e kodimit të API është triviale. Në rastin tonë, ne e kemi përdorur implementimin e Red&Black Tree nga libri Algorithms, 4th Edition (Robert Sedgewick & Kevin Wayne) që e ofrojnë kodin e implementuar ne Java dhe mund ta gjeni në këtë link. Kodi është përkthyer në C# dhe është implementuar si një API që mund të thirret me një HTTP GET. Të dhënat e IP rangjeve janë të ruajtura në SQL Server. Në startimin e API lexohen të gjitha rangjet e IP adresave dhe formohet pema që ruhen në RAM memorie. Më pas të gjitha kërkesat kthehen nga RAM memoria dhe nuk shkon më në databazë. Kjo do të thotë që në fillim API vonon deri në disa sekonda për t'i lexuar të gjitha rangjet e mundshme nga databaza.
Këtë API e kemi implementuar rreth 2 vjet më parë (në 2016) dhe që nga atëhere përdoret nga të gjitha produktet tona. Mesatarisht në ditë ky API proceson rreth 10 milionë kërkesa të ndryshme dhe ka një kohë të përgjigjes më të vogël se 10 milisekonda (varësisht prej rrjetit dhe largësisë nga serveri). Përditësimin e IP rangjeve e bejmë në mënyrë manuale në rast nevoje.
Çdo pyetje shtesë, koment apo sugjerim është i mirë se ardhur.

